
ユーザーの対話指示と、人間の評価を反映した強化学習により構築されたChatGPTが広く普及している昨今。
このような主要LLM(Large Language Models:大規模言語モデル)は英語モデルが主となっており、日本語に特化したLLMの開発が国内大手ベンダーを中心に進められているといいます。
しかし、具体的な学習方法が不透明であることや、クラウド運用前提など、セキュリティ面での懸念が多いことから、特に企業での実運用には課題があるようです。
そんななか、東大発AIスタートアップのLightblueは国内で公開されているモデルとしては最大規模とされる67億パラメータを有する日本語LLMを開発し、オープンソースで公開しました。
セキュリティと透明性に優れたLLMモデルのオープンソース化で、AI活用の幅を拡大するとのことです。
専門用語を理解するようLLMを訓練
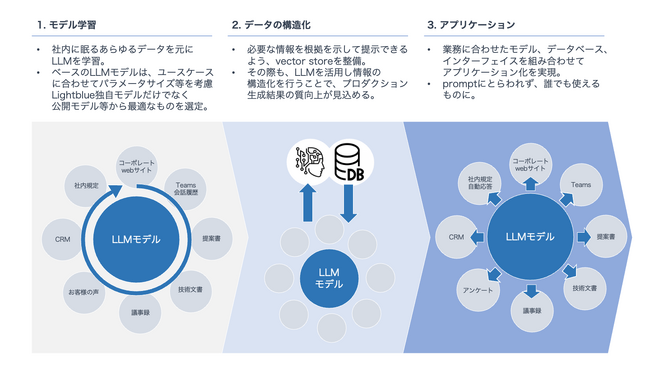
Lightblueは、LLM導入にあたり「各法人や各部署の特定ニーズへの対応」「セキュリティ」「透明性」の3つのメリットを十分に発揮できるよう、ソリューションを提供します。
同社は業界用語や部署特有の専門用語、あるいは慣習などに合わせてLLMの調整・訓練を実施。例えばIT関連の部署では、コーディング用語や最新の技術トレンドなどの専門用語を理解するようLLMを訓練します。
これにより、LLMはソフトウェア開発の文書化、バグレポートの分析、テクニカルサポートの提供など、特定のタスクに特化した支援を提供することが可能です。
生成AI・LLMの運用に関する透明性を担保
LightblueのLLMはオンプレミス環境で利用できるよう構成されており、ユーザー個別のニーズ・環境に応じた安全な専用環境を提供します。また、パブリッククラウドとの連携も強化し、情報漏洩リスクへの対策を強化します。
学習データや学習方法がわかっているモデルを用いることで、生成AI・LLMの運用に関する透明性を担保。さらに、Lightblueでは学習済みモデルやAPIの評価ができる監査機能を提供します。
具体的には、モデル全体の重みの分布の比較、生成結果の精度評価、生成結果と学習データの関係の評価などについて、より深い理解と信頼の獲得を実現するとのこと。
これは、医療情報や歴史事実などの情報精度、生成結果が誹謗中傷を発しないかなど、社内のLLM活用の情報監査に利用できる重要な技術です。
実用的なLLMの実装をサポート
 今回、Lightblueは生成AI特化開発チーム「LLab」を設立。
今回、Lightblueは生成AI特化開発チーム「LLab」を設立。
同チームでは、建設や製薬など「業界・法人ごとの専門用語が多い現場」、金融や医療など「高レベルのデータ侵害対策が必要な現場」、工場や建設現場など「通信環境の整備が難しい現場」における実用的なLLMの実装をサポートします。
今後は、オンプレミスで個社に合わせた独自モデルを提供することはもちろん、DXコンサルティングおよび受託開発で培ったノウハウをフル活用し、各社・各部署・現場ごとの業務理解を基盤としたカスタマイズを実施するとのこと。また、公開モデルを用いた自社サービスの提供も予定しています。
参考元:https://prtimes.jp/main/html/rd/p/000000047.000038247.html
(文・Haruka Isobe)
- Original:https://techable.jp/archives/214728
- Source:Techable(テッカブル) -海外・国内のネットベンチャー系ニュースサイト
- Author:はるか礒部
Amazonベストセラー
Now loading...