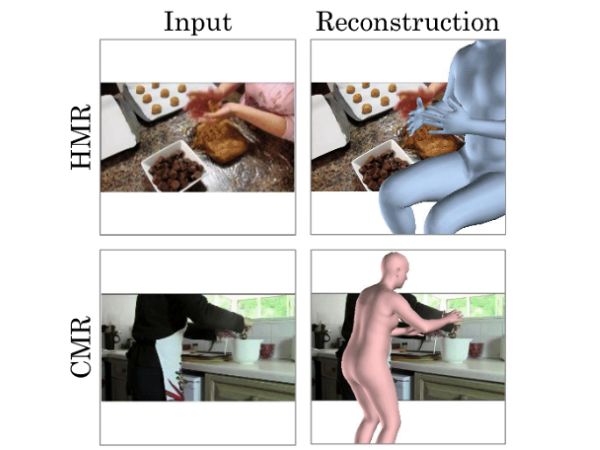
現行のAIは、全身が表示された動画ライブラリにてトレーニングされており、身体の一部だけが映った動画の認識精度は極端に落ちる。また、基本的にトレーニングに利用される動画には人手でラベルが付けられる必要があった。
ただ、Web上に公開されている動画では、全身を正面から見られるものはわずか4%程度とのことで、もちろんラベルも付いていない。
Web上の膨大な動画を利用可能にするべく、ミシガン大の研究チームは、身体の一部だけしか映っていない動画からポーズを推定するAIを開発した。
3D人間に落とし込んでポーズを推定
How can we understand humans in internet video? Our #ECCV2020 work presents a simple but highly effective method for self-training on unlabeled video! We annotate four datasets to evaluate & show large gains.
Project Page: https://t.co/tLLNqkLqhS
arXiv: https://t.co/nW0WOJNfUP pic.twitter.com/xx39I6UJAA— Chris Rockwell (@_crockwell) August 14, 2020
我々が身体の一部しか映っていない動画からポーズを推定できるのは、その人がどういった状況でなにをしているのかを無意識に理解しているからだ。例えば、キーボードと手の動画を観れば、タイピングしている人の身体が想像でき、場合によっては立っているか座っているかまでわかる。
前提条件に関する認識を持たないAIに同じことをさせるには骨が折れそうだ。ただ、研究チームのとったアプローチはシンプルなもので、身体の一部が映った動画のフレームごとに、ニューラルネットワークモデルが3D人間に落とし込んでポーズを推定する。
まず研究チームは、トレーニング用のデータセットを切り抜くことで、Web上の動画のように身体の一部だけが見える状態にした。具体的には、もともと全身が映っていた動画を、胴、頭、腕だけ映った状態にして、既存のモデルを再トレーニングしたようだ。結果このモデルは、Web上の動画からもポーズが推定できるようになったという。
セルフトレーニングが可能
また研究チームは、ニューラルネットワークが自身の生成した推定結果を用いてトレーニングできるようにした。さらには、被写体のアングルが微妙に異なる複数のフレームをトレーニングに利用。通常のAI画像認識では「人(80%)ネコ(20%)」といったかたちで信頼度を表すが、自信のないものは被写体のアングルがちょっと変わっただけでまったく別の結果になるという。この現象を利用して、モデルが自身で信頼度の低いフレームを破棄できるようにした。
こうした手法を組み合わせることでセルフトレーニングが可能となり、人によるラベル付けが不要になったとのこと。
今後研究チームは、フレーム内のオブジェクトや、そのオブジェクトを使って人がなにをしているかまでモデルが予測できるようにする。これが実現すれば、環境をより深く理解できるAIの開発につながるだろう。
参照元:New research teaches AI how people move with internet videos/ The Michigan Engineer News Center
- Original:https://techable.jp/archives/137453
- Source:Techable(テッカブル) -海外・国内のネットベンチャー系ニュースサイト
- Author:YamadaYoji
Amazonベストセラー
Now loading...